C++模板的编译与链接
最近在工作中又遇到了个很大的问题,我在编译自己写的某个库的时候,时间异常地长,如果选择make的线程数量太多(make -j8之类的)甚至会因为内存原因被kill。编译时间也就算了,我左思右想到底哪里会让一个编译的过程需要那么多的内存,整整8G是怎么被编译吃满的。最后我的目光落在了一些模板类上,也由此对模板了解得更加深刻了些。这篇博客主要关注的不是模板的用法,什么继承模板类啦、Non-type模板啦都不会讨论,我们主要讨论模板类编译时是怎么被完成的。
Inclusion Model vs. Explicit Instantiation
首先写一个模板,一般来说会有两种写法。你会常常看到模板在.h文件里被全部定义并实现(definition & declaration),偶尔也会看见.cpp中才去实现的模板,但你会在这些cpp文件中看到一些奇怪的实例化句子。这两种方法被分别称为Inclusion Model和Explicit Instantiation,让我们首先从他们俩开始。
需要注意的是,其实还有一种使用export关键字来完成模板定义的方法(也被称为separation model)。但它直到C++20之前都并不是官方标准,在C++11就已经被删除(但reserved),我们今天先不讨论。
Inclusion Model
Inclusion model指的就是在.h / .hpp的头文件中直接实现所有的模板定义。
1 | // Foo.h |
这样定义好后,在其他任何include了本头文件的文件中,都可以随便实例化各种模板类。对所有合法的类型T,使用Foo<T>不会有任何报错。
这也是我们平时最常见的模板实现方式,但它也实际上是我编译时间、内存消耗的罪魁祸首。
Explicit Instantiation
Explicit instantiation会在源文件中(.cc / .cpp / .cxx)再实现模板,头文件中仍旧会只有declaration。
1 | // Foo.cpp |
我们会看到最后一行就是我们显式地声明————我们要有一个Foo<int>的模板类。此时如果你在某个源文件中另外使用Foo<bool>,程序会直接报错,因为这个模板类并没有被实例化过。
那么现在问题来了,假设我们还有一个源文件Bar.cpp也包含了Foo.h如下
1 | // Bar.cpp |
我将Foo.cpp和Bar.cpp链接在一起生成可执行文件。如果模板函数 / 类模板是一般的函数 / 类,Foo<bool>自然能在foo.h中找到定义并在foo.cpp中找到实现,可是实际情况却是————Linker出了问题,它会找不到Foo<bool>的定义!接下来我们就来看看模板到底如何被编译,以及为什么会有这样的问题。
模板的编译
第一步来让我们写个模板看看编译出来的文件是什么样的吧!假设咱们使用Inclusion Model,Foo.h就是第一小节中所定义的那样。然后我们在源文件中include它并随便乱写一个main函数用O0编译。
1 |
|
看到汇编后你会惊讶地发现,一行关于模板的代码都没有!
1 | pushq %rbp |
而当你随便加一行实例化的代码之后,你就会发现关于模板的代码出现了。这告诉我们,当编译器看到模板代码的时候,实际上它什么都没有做!而真正让它generate出代码的是,是实例化的那一行!
模板是一种Pattern
由上面的例子我们知道了,你在写的类模板更像是一种“宏”,它对编译器来说只是一个生成代码的方式,而不是代码本身。只有当编译器遇到了实例化的代码时,它才会去生成对应的代码。可是这里就会带来第一个问题,我们知道对一般的函数来说,编译器生成符号之后,任何调用该函数的地方就只需要这个函数的declaration而不需要definition了,而模板需要到了实例化的时候再生成代码,那岂不是我们必须要既有declaration又有definition才能用?
这个看起来有些愚蠢的问题答案确实是的。这也是为什么Inclusion Model需要我们把所有定义都写在头文件————在源文件include时,自然而然地所有的定义都在,实例化也就不会遇到任何阻力了。同理对Explicit Instantiation来说,上一节的Bar.cpp会有Linking的问题,因为它并没有include包含类模板实现的源文件Foo.cpp(虽然这听起来有点奇怪,但如果你加上一行#include "Foo.cpp"那么链接错误就会消失了)。
接踵而来的第二个问题是,很明显所有要实例化这个类模板的源文件都需要include该头文件,难道每个源文件都要带一份这样实现的拷贝吗?
很不幸回答也是肯定的,这也是为什么我的程序会有内存爆炸的问题————当一个大类模板被无数的源文件include,并且每个源文件都在疯狂实例化这个类模板时,大量的这样的拷贝会被生成占用大量的内存空间。更准确地说法是,每个编译的translation unit都会带有被实例化的模板类代码的拷贝。
需要注意的是,这个实现对不同compiler来说本质上是不一样的。但是gcc用的是这种greedy的策略。
当你理解了模板的编译,你就不难理解Instantiation Model的合理性了————该文件中拥有了definition & declaration,所以它可以随意地实例化模板类。而由于它已经实例化了模板类,与它链接的文件如果用到的是同样的实例化的模板类,就不会有找不到定义的问题了。到这儿也不难看出两者的优劣,Inclusion Model的问题就是我所遇到的内存、编译时间爆炸的问题,而Explicit Instantiation则太难去完整的考虑你到底需要用到哪些实例化的模板,还容易在不同的文件中重复定义,但却满足了隐藏模板类实现、编译加速的条件。
但讲到这里,又会带来下一个问题,每个源文件都带这样一份拷贝,假设我有好几份源文件都实例化了Foo<int>,那链接在一起岂不是就重复定义了吗?下一章我们来讲链接器的操作。
模板的链接
这一章其实并没有太多要说的,因为根据gcc官方的文档,链接器会检查所有translation units中的模板实例化,并且最终只保留一个,而由此你的二进制文件也不至于太大。
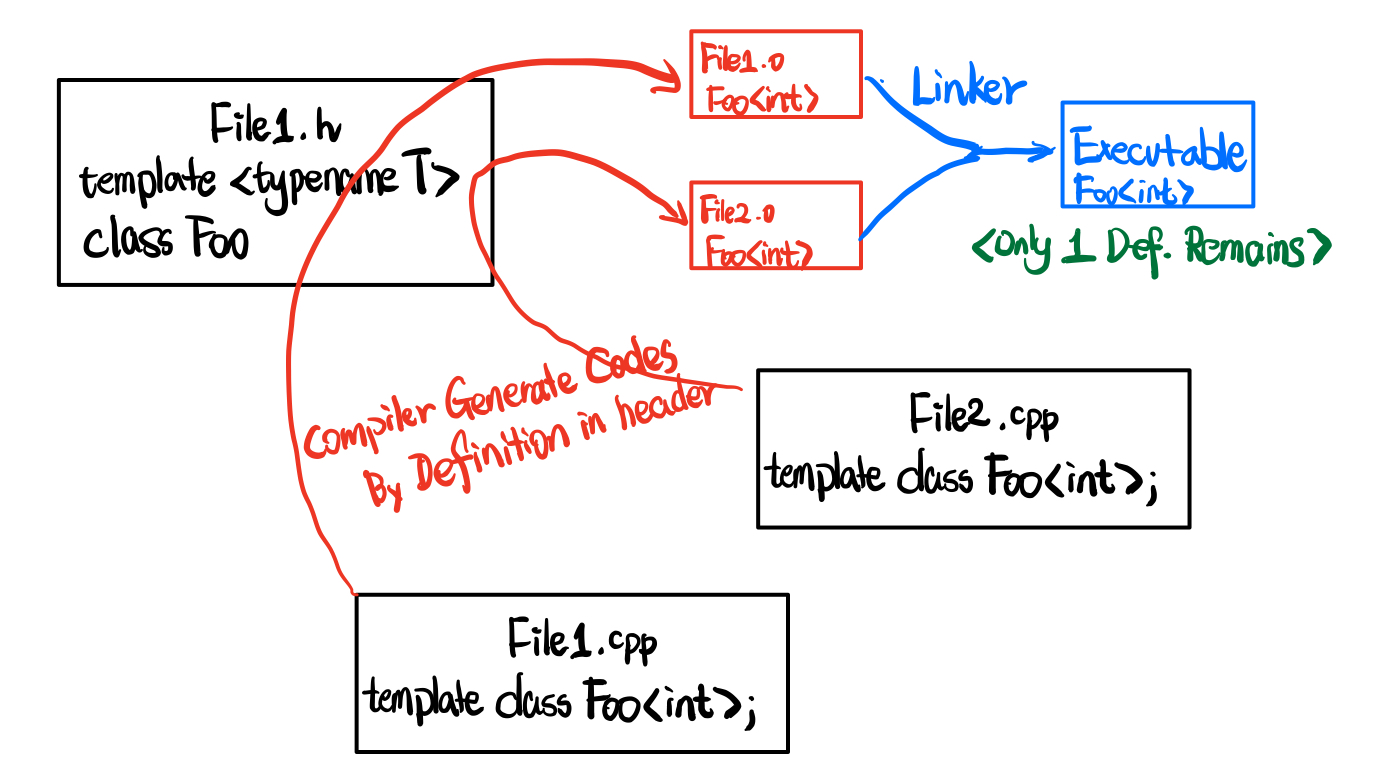
模板特化
特化的模板是什么呢?很显然已经不可能再是我们前面所说的一种“宏类似物”了,它就是一个函数模板的实例化,链接器会把它当成一个普通的函数处理。这也是为什么如果你使用的是Inclusion Model,特化模板函数前面必须要加上一个inline关键字,否则就会违反ODR。
最后讲一个与今天想讲的模板编译并没有太大关系的小技巧,也算是在这次project中学到的一点东西吧。当你需要特化一些模板,可是特化的模板函数明明和大众的模板函数有大量的重复,如何节省代码呢?C++官方的模板文章里讲到,我们应该把公用的部分放到一个公共的parent函数里,specialization中只做小部分不同的codes。
1 | template<typename T> inline void foo_part(const T& x) { |
最后的最后,C++17开始能够支持一种特殊的特化方式可以更为简洁,就是使用type_traits来进行模板的不同操作。需要注意的是,C++17之前没有if constexpr,这样的做法会使程序变慢(你将一个编译器常量放到了运行时)
1 | // Implementation |
但是同样的,这样的写法上面所说的Inclusion Model所存在的问题并不会改变。所以最好的还是把common codes移到某个非模板的inline函数里。
附录
A.1 One Definition Rule
- Every non-inline functions / member functions / global variables / static data members should be only defined once across the whole program.
- Inline functions / class types should be defined only once in one translation unit and all of these definitions should be the same