同步语义(Synchronize-with)和Acquire-Release Fence
This article is partly referred to & translated from Jeff Preshing’s blog. Personal thoughts added.
在第一篇技术博客里,我们就提到了同步语义(Synchronize-with)的重要性。问题在于,在多线程的环境下,谁也不知道处理器实际执行程序的顺序如何。可是我们程序的正确执行,往往需要一个合理的顺序,例如第一个线程需要读共享变量B,然而第二个线程会修改B。我们需要告诉处理器,到底谁是先执行的那一个。
而同步语义就是这里的屏障,它保证了某个线程的某些内存操作(甚至可能是non-atomic的)对其他的某个线程的某些操作来说一定可见。
这篇文章想讲明白实现同步最重要的方法之一 ———— Acquire & Release Fence。
在正式开始之前,我们需要知道在同步语义里,一般都能找到两个最关键的变量,分别是guard variable和payload。其中payload是线程间共享的变量,而guard variable人如其名,保护对payload的访问权限。现在我们可以开始来看大名鼎鼎的Acquire & Release Fence了。
理解Acquire & Release Fence
直接的表达两者的作用即
Acquire Fence防止重排任何屏障之前的读操作 & 屏障之后的读写操作。
Release Fence防止重排任何屏障之前的读写操作 & 屏障之后的写操作。
用我们在内存屏障的博客里讲的概念来说,Acquire Fence就相当于#LoadLoad + #LoadStore屏障,而Release Fence则等同于#StoreStore + #LoadStore屏障。
接下来我们通过一个经典的例子来理解Acquire & Release Fence。假设我们通过Message类在多个线程间进行通信,用g_payload和g_guard来表示这个同步语义中的payload与guard variable
1 | struct Message { |
通信的两个函数分别如下
1 | void SendTestMessage(void* param) { |
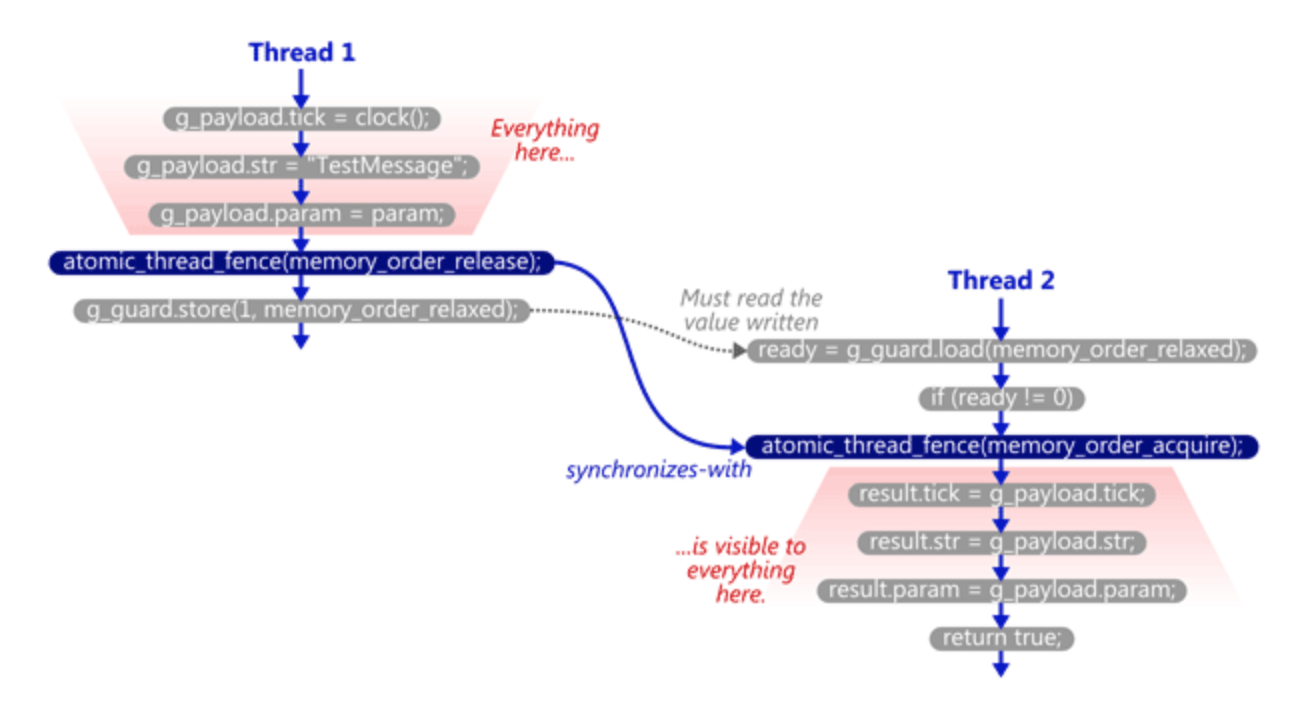
当g_guard在TryReceiveMessage函数中load为1时,Acquire Fence会启动,从而保证了同步语义。我们假设线程I运行SendTestMessage而线程II运行TryReceiveMessage,程序具体的运行如下:
- 线程I在处理器本地进行了一些对
g_payload的非原子性存储操作 - 线程I启动了Release Fence ———— 线程I进行下次存储操作之后,所有它之前所进行的内存操作都会被其他线程看到
- 线程I将值1存到
g_guard中,注意此时由于Release Fence的存在,所有的内存操作已经同步到了其他处理器中(硬件层面的理解请参考之前的博客) - 一段时间之后线程II看到了
g_guard的修改,并且进入了if分支 - 线程II启动了Acquire Fence ———— 线程II保证了读到的payload的值至少和上一次读操作一样新(因为我们用Acquire Fence保证了先读
g_guard再读g_payload),至此同步语义完成
Release Fence vs. Release Operations
我们在DCLP的博客中,曾见到过类似atmoic_var.load(sth, std::memory_order_release)的Release Operation。值得注意的是,它和Release Fence并不等价!Release Fence可以完成Release Operations的功能,但反过来则并不是如此。参考以下的例子:
1 | // Release Operations |
比起Fence,Release Operations实际上对内存操作重排(Memory Reordering)的限制要更少。Release Operation只保证了不会重排它之前的任何读写操作 & 这次store操作。而Release Fence则保证了不会重排此前任何的读写操作 & 之后所有的写操作。对Acquire Fence及Acquire Operations也是同理。
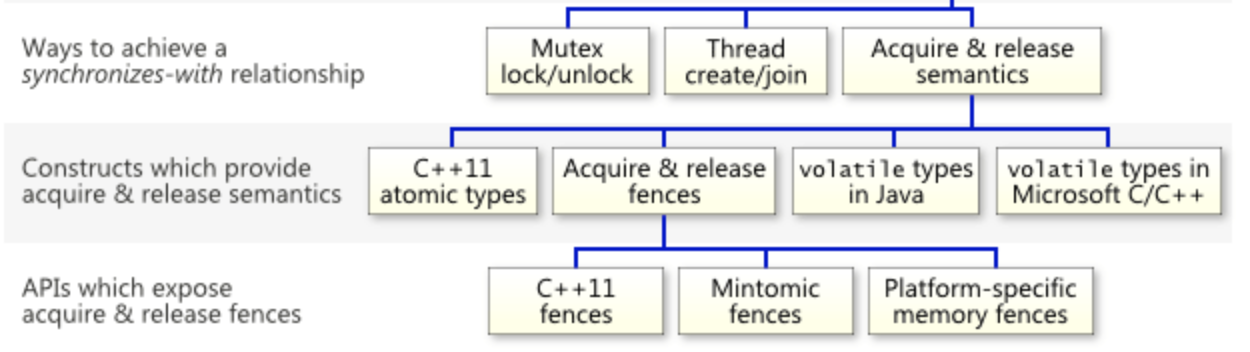
其他实现同步语义的方式
Acquire / Release Fence仅仅是实现同步语义的一种方式。实际上C++11之后,实现它的方式变得多种多样。Jeff整理并列出了以下的这些同步语义的方法(但并不完整~)