内存屏障(Memory Barriers)【下】————从硬件的角度看内存屏障
This article is partly referred to & translated from Paul’s Memory Barrier Paper. Personal thoughts added.
上篇博客,我们通过Git的想法来入门了内存屏障(memory barrier)。但是如果你仔细的研究过,你就会产生新的问题————为什么memory reorder会发生?保证两个操作之间的相对顺序,听起来这么炫酷的操作硬件是怎么实现的?本篇博客将尝试讲明白上面的问题,但它需要你拥有一定的计算机体系结构(architecture)知识,以及不少的时间。
回顾体系结构
缓存一致性的MESI协议
为了保证多核系统下的缓存一致性,计算机科学家们建立了一系列缓存一致性协议。它们非常非常复杂,我们在这讨论相对简单的MESI协议。对于每个CPU的L1-Cache的任何Cache Line,我们定义如下四种状态(State)
- Modified - 即表示此CPU改动了内存中对应的数据,且此条Cache Line为此CPU独有,不可能出现在其他CPU缓存。也因此在本Cache Line被flush之前,此CPU必须保证数据已经写入内存 / 共享至其他Cache
- Exclusive - 表示此CPU独有该条Cache Line,且即将有修改进行,但此时Cache Line中的数据仍旧和主存一致
- Shared - 表示至少有其他一个CPU共享本条Cache Line,且Cache Line中的数据是最新的,和主存一致
- Invalid - 表示本Cache Line没有数据或数据无效
同样我们需要定义协议下的6种消息
- Read - 读某个地址的数据
- Read Response - 回复Read消息,包含了对应地址的数据。需要注意的是,数据可以从主存而来,也可以从某个Cache而来
- Invalidate - 要求其他Cache删除对应地址的Cache Line
- Invalidate ACK - 回复Invalidate消息,表示本CPU已经删除了对应Cache Line
- Read Invalidate - 相当于Read + Invalidate,所以需要Read Response + Invalidate ACK的回复
- Writeback - 写出Modified State的数据到主存
四种状态之间的相互转移方式(Row State -> Column State)如下
| From/To | Modified | Exclusive | Shared | Invalid |
|---|---|---|---|---|
| Modified | / | CPU将data写回主存并保留在Cache,需要发出Writeback信号 | CPU收到了其他CPU的Read消息,将data发送给对应CPU并发出Read Response | CPU收到了Read Invalidate消息,需要无效化本地的data并将其send给对应CPU,发出Invalidate ACK和Read Response |
| ———– | ———– | ———– | ———– | ———– |
| Exclusive | CPU写data进入Exclusive的Cache Line | / | CPU收到了其他CPU的Read消息,将data发送给对应CPU并发出Read Response | 其他CPU进行了类似RMW的原子操作,该CPU收到Read Invalidate消息,需回复对应ACK |
| ———– | ———– | ———– | ———– | ———– |
| Shared | CPU进行了类似RMW的原子操作,需发生Invalidate操作并等待Invalidate ACK之后完成状态变化 | CPU知道自己即将修改数据并发送了Invalidate操作,同样地需要等待Invalidate ACK | / | 其他CPU进行了Store操作,本CPU收到Invalidate消息,需回复对应ACK |
| ———– | ———– | ———– | ———– | ———– |
| Invalid | CPU进行了类似RMW的原子操作,发生Read Invalidate并等待回复 | CPU进行Store操作且写Miss,发送Read Invalidate并等待回复 | CPU进行Read操作,等待Read Response回复 | / |
Store Buffer及Invalidate Queue
为了加速缓存,体系结构里有无数的精巧设计。想像一个如下所示的最经典的计算机体系结构层级,两个CPU,每个带有一个Cache,共享L2-Cache及内存。
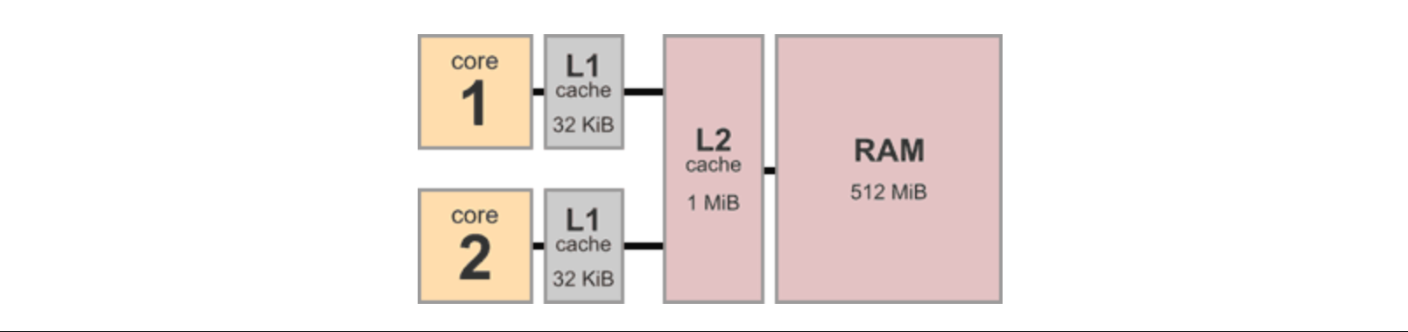
随之而来的问题是,根据我们上面的协议,假设CPU 0需要从Cache写某个数据到内存(从Shared到Modified),我们需要发送一个Invalidate消息。此时这个CPU只能停下自己的脚步,等待其他CPU回复Invalidate ACK,在此之前它失去了自己作为CPU的意义。那么如何减轻这个overhead呢?
那么请问假设作为可爱的大学生的你有一堆deadline,可是实验室有个虽然实验还没跑但你100%确定结果的实验,需要你现在立刻告诉教授结果。你会怎么做呢?答案当然是————直接给教授发结果,实验以后再做先把ddl赶完。CPU和Cache的优化思路也是一样:
- CPU写数据时,如果数据并非Exclusive或Modified,我们把这个操作放到一个Store Buffer里,接着干其他的事,收到Invalidate ACK之后再进行写操作
- CPU收到Invalidate消息时,先不去Invalidate,只把这些放在一个Invalidate Queue里,直接回Invalidate ACK并干其他的事,直到真正需要用到这个Cache Line时再扔掉就好
据此,我们设计出了下面这个精巧的体系结构
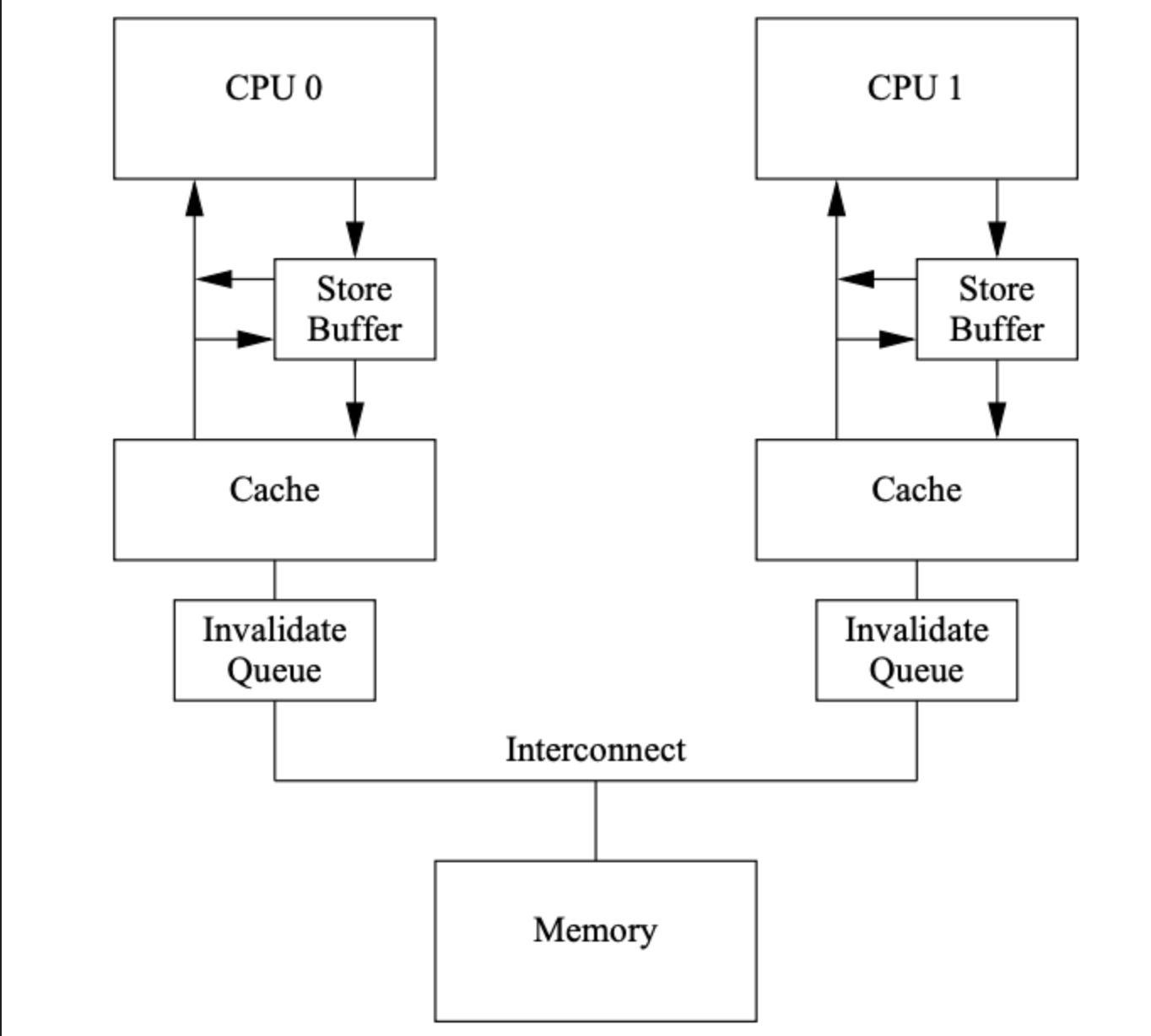
每当CPU想要store时,我们将其先存入Store Buffer并不限期延时本次store操作(load也是同理)。而这本质上就是指令重排————并不是CPU真的把两个指令的顺序调换,而是某一个指令进入buffer并未实际执行就继续了!这也是为什么在上篇博客我们说
由于处理器重排(processor reordering)的存在,修改何时写入内存是未知的
由四种内存屏障(Memory Barrier)看指令重排(Instruction Reordering)的本质
接下来我们将在#LoadLoad & #StoreStore的使用场景下举一个经典的例子,把整个过程break down到最底层。读完以下的小节我们就能知道到底“指令重排”这四个字意味着什么,以及为什么内存屏障不可或缺。
#StoreStore内存屏障
考虑以下的程序分别在系统的两个core上运行,初始a = b = 0且分别存在CPU 1 / CPU 0的Cache中。
| CPU 0 | CPU 1 | Cache 0 | Cache 1 |
|---|---|---|---|
| a = 1; | while (b==0) continue; | b = 0 | a = 0 |
| b = 1; | assert(a==1); |
考虑以下这个运行序列:
- CPU 0执行
a = 1,在写时发现Cache Miss- 为了从Invalid状态切换为Exclusive状态,发送Read Invalidate消息
- 如上一节所言,我们的CPU很忙碌,于是CPU 0把写操作放到了Store Buffer中,还未执行
- CPU 1执行
while (b == 0),读时发现Cache Miss,发送Read消息 - CPU 0执行
b = 1,写命中且b为Exclusive,于是直接执行 - CPU 0收到了CPU 1的Read消息,将
b = 1通过Read Response发回给CPU 1 - CPU 1收到了Read Response,结束了循环并运行
assert(a==1)<– 失败! - CPU 1收到了Read Invalidate消息,将
a移出自己的Cache Line,可是为时已晚
在整个上面的运行过程中,我们只字未提处理器将某两个命令reorder,看似一切都按顺序在进行,但是思考这整个运行过程,出现的本质问题不就是a = 1和b = 1在CPU 1的世界里反过来了吗!
现在我们假设在a = 1和b = 1之间加入#StoreStore内存屏障(从这个例子里你会知道内存屏障是怎么实现的!),上面的运行序列就会变成
- CPU 0执行
a = 1,在写时发现Cache Miss- 为了从Invalid状态切换为Exclusive状态,发送Read Invalidate消息
- 如上一节所言,我们的CPU很忙碌,于是CPU 0把写操作放到了Store Buffer中,还未执行
- CPU 1执行
while (b == 0),读时发现Cache Miss,发送Read消息 - CPU 0执行
#StoreStore()内存屏障,此时CPU 0会标记Store Buffer中的值,即a - CPU 0执行
b = 1,此时由于Store Buffer中存在标记值,该store操作再次被放入Store Buffer - CPU 0收到了CPU 1的Read消息,将
b = 0(由于b = 1还未执行)通过Read Response发回给CPU 1 - CPU 1收到了Read Response,但此时
while (b == 0)循环成立并继续运行! - CPU 1收到了Read Invalidate消息,将
a移出自己的Cache Line,并发送Read Response & Invalidate ACK - CPU 0确认ACK完成
a = 1的存储,在运行b = 1时再次发出Invalidate消息(由于b为shared) - CPU 1移出
b = 0并发送Invlidate ACK - CPU 0确认ACK完成
b = 1的存储 - CPU 1运行
while (b == 0),读时Cache Miss并发送Read消息 - CPU 0回复Read Response并将
b = 1传给CPU 1 - CPU 1成功跳出循环并运行
assert(a == 1)<– 成功!
内存屏障成功的阻止了“重排”!回到我们大学生的例子,你既有实验室的实验要做又有其他ddl,作为教授我的方式就是————把实验也设一个ddl,且这个ddl并不是具体的时间,而是“比你其他ddl先完成”!那么无论如何,在完成你的其他ddl之前,你都必须做完这个实验。
#LoadLoad内存屏障
和上面类似的程序,不过这次我们已经加入了#StoreStore屏障,且a现在是shared状态。
| CPU 0 | CPU 1 | Cache 0 | Cache 1 |
|---|---|---|---|
| a = 1; | while (b==0) continue; | b = 0 | a = 0 |
| #StoreStore() | assert(a==1); | a = 0 | |
| b = 1; |
类似地,考虑以下的执行序列
- CPU 0执行
a = 1,由于Cache命中,发送Invalidate消息,并将操作塞入Store Buffer - CPU 1执行
while (b == 0),读时Cache Miss发送Read消息 - CPU 1收到了来自CPU 0的Invalidate消息,由于太忙碌将其放入Invalidate Queue,发送ACK
- CPU 0收到了Invalidate ACK并依次执行
a = 1/#StoreStore()/b = 1a = 1执行完成后,Store Buffer此时为空,#StoreStore()可视为NOPb = 1发生写命中且为Exclusive,直接写入Cache
- CPU 0收到了来自CPU 1的Read消息,将
b = 1随Read Response传回CPU 1 - CPU 1收到Read Response并跳出循环,执行
assert(a == 1)<– 失败!- WHY:此时CPU 1并未执行此前的Invalidate!所以
a仍旧在Cache 1中且值为0!
- WHY:此时CPU 1并未执行此前的Invalidate!所以
- CPU 1执行Invalidate Queue中的消息flush缓存中的
a,可是为时已晚
注:这部分我认为论文本身写的有些问题所以有所修改,但鉴于论文作者是巨佬,我也不太敢100%保证自己正确,推荐有兴趣的读者自行翻阅论文比对,根据自己的理解选择正确的版本^^
同样的,在整个上面的运行过程中,我们只字未提处理器将某两个命令reorder,但出现的本质问题还是类似的,即在CPU 1的世界里,我们先load了a再load的b!加入#LoadLoad屏障即可如同#StoreStore地解决问题,这里不再赘述(不同点就只是mark的不是Store Buffer而是Invalidate Queue罢了)。
抛开处理器谈Memory Barrier的人是流氓
我们讲了两篇博客的Memory Barrier,或许使你十分兴奋————你懂了这么多酷炫的知识!但是很不幸的是,不同的处理器的内存模型是不一样的,很多处理器其实并不需要我们考虑那么多(比如某些处理会禁止CPU那么懒,禁止#LoadLoad / #StoreStore的重排)。而我们常见的Intel x86-64系统,是个强内存模型的系统,即我们仅仅只需要考虑#StoreLoad一种重排情况。
不过不必灰心,首先在大多数你并不知道其内存模型的系统上,或者说你需要写跨平台的代码的时候,你需要它们。其次在本系列博客的最后一期大家会看到,这些知识对我们理解C++11的memory model有着很好的帮助。当然最重要的,它们很酷炫啊!
详细的各个处理器的内存模型可以参考Paul的论文第七节。当然时间可能有些久远,以Intel x86-64为例则需要参考对应的Intel 64软件开发指南第八章。