内存屏障(Memory Barriers)【上】————什么是内存屏障
This article is partly referred to & translated from Jeff Preshing’s blog. Personal thoughts added.
如果你用过git一类的版本控制工具,那么你已经走在认识内存序(Memory Ordering)的路上了。上一篇博客中我们提到了内存序的第一部分,即编译器层面的内存序。这一篇博客将尝试从处理器的角度考虑内存序,即处理器指令重排(Processor Reordering)的问题。和编译器一样,处理器重排的基本规则也同样是不影响单线程程序。不一样的地方在于,处理器的重排仅仅会在多核系统(Multi-core system)下造成问题。
你可以使用内存屏障(Memory Barrier)来保证处理器层级的内存序(一般来讲这是programmer唯一需要考虑的内存序,因为编译器级别的内存序一般都已经隐性的保证了),一些常见的内存屏障操作如下:
- 某些内嵌的汇编,比如PowerPC-specific
asm volatile("lwsync" ::: "memory") - C++11 atmoic类型的很多操作,比如
load(std::memory_order_acquire) - POSIX锁操作,比如
pthread_mutex_lock
内存屏障本身也是多种多样的,不同的内存屏障也会产生非常不一致的内存序。本篇博客关注内存屏障本身,想讲明白各种内存屏障的类型,以及它们是为什么场景而生的。
用Git来思考内存屏障
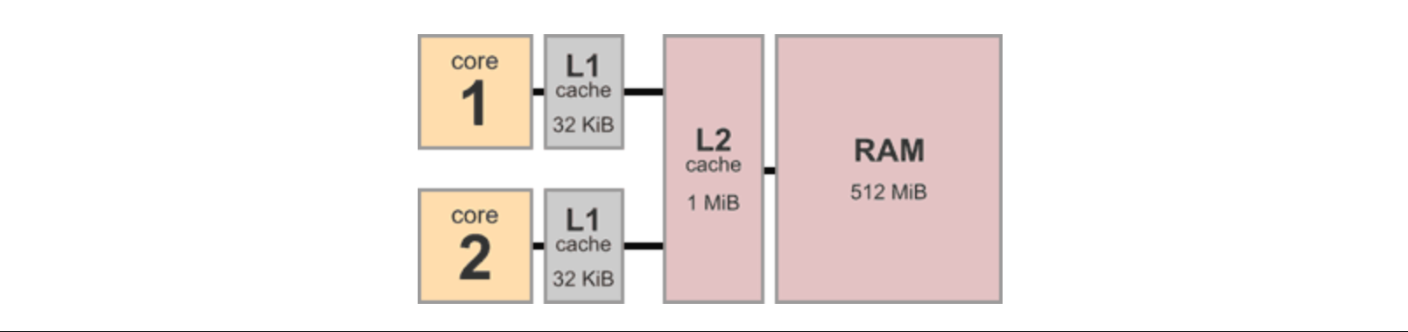
假设我们在下面的多核系统上进行我们的实验,每个核独自拥有32KB的L1缓存、核共享1MB的L2缓存及512MB的内存。我们把想要完成的任务看做是一个github project,那么每个核就成了一个参与其中的程序员。在我们所说的这个例子里,即有两个程序员在同时开发这个程序,为了后续的讲解方便,让我们给他俩分别命名为Larry / Sergey (图源Jeff的博客)。
对比实际的场景,远端的repo表示了内存和共享的L2缓存的集合,两位程序员在自己的本地对repo的拷贝(clone)也就表示了每个CPU核自己独享的L1缓存。他们各自在自己本地的分支上疯狂地修改代码,就像是在不同核上正在跑的不同线程的程序。类似地,当处理器上的程序完成了修改,将修改同步到内存可以看成是程序员在push代码。另一个处理器从内存load相应的改变则就像程序员pull代码。
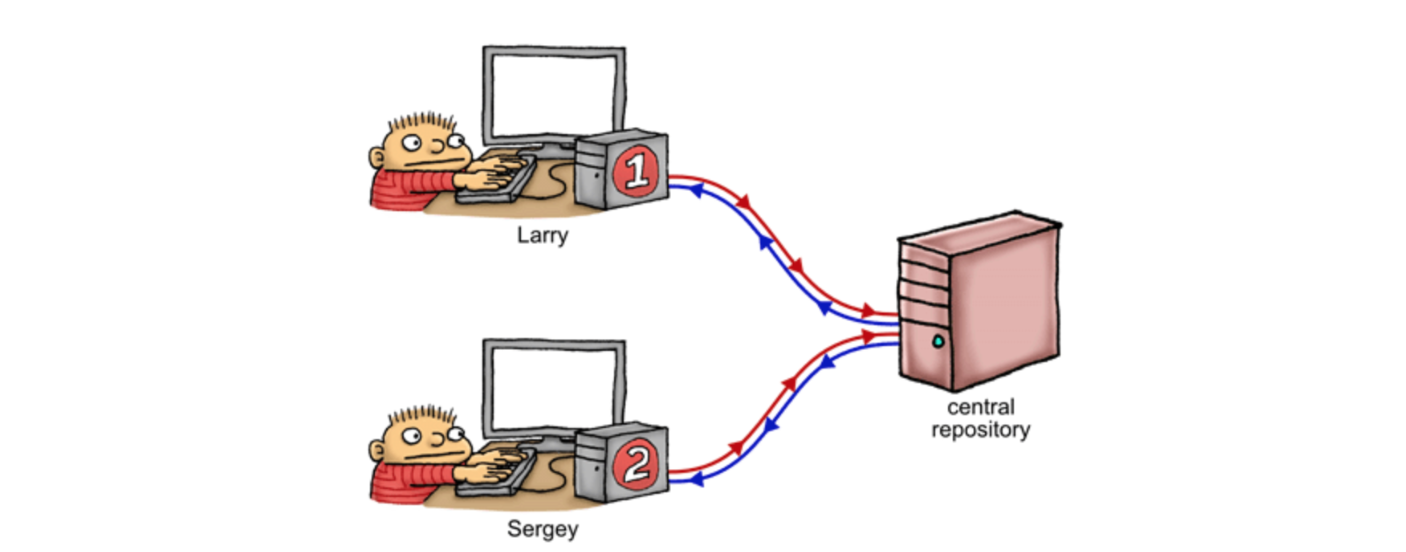
当然系统和实际的版本控制程序员开发仍旧有所不同,因为系统内的修改是在自动地、在未知的时间里同步到系统内存(push到远端)的。举例来说,假设Larry修改了变量X,这个修改一定会最终影响主存中变量X的值,但问题是,由于处理器重排(processor reordering)的存在,这个修改何时写入内存(被push到远端)是未知的!如果Larry还同时修改了变量Y、Z,我们也同样无法知道是Y、Z的修改先写入内存,还是X的修改先写入内存。当然同样地,这里处理器的重排一定保证单线程的正确性。这个例子里,我们可以看到处理器为了加速程序,可能以我们未曾设想的方式在重排存储(store)操作。
类似的事情在Sergey的一侧也在同时发生。假设Larry的修改已经进入了内存,但内存何时把修改放入Sergey侧的L1缓存(pull远端的改变),我们也不知道————处理器同样在重排读取(load)操作。
接下来假设我们的两位程序员开始在这个project上共同工作,且我们的设计并没有好到让他们的工作完全解耦————他们在共同操作以下的全局变量X和Y(都初始化为0)。如下所示,Larry首先store X然后load Y,而Sergey相反先store Y再从远端load X。
| Processor 1 (Larry) | Processor 2 (Sergey) |
|---|---|
| mov [X] 1 | mov [Y] 1 |
| mov r1 [Y] | mov r2 [X] |
Larry、Sergey分别在他们的本地将X / Y修改为1,理论上来说他们再分别读Y / X时,至少有一个人(processor)会读到1。但反直觉的事情是,在x86-64的Intel系统(参阅Volume 3, §8.2.3.2的例子,也就是上面的这个例子)下,Larry、Sergey可能会分别读到0!这里的原因就是指令重排!
考虑两个处理器分别重排了两边的操作,即Larry / Sergey都是把Y / X读到本地,再进行写操作————单线程的情况下又一次不会有任何问题!可是此时Larry和Sergey都将先读到一个0,再进行各自的load操作。
| Processor 1 (Larry) | Processor 2 (Sergey) |
|---|---|
| mov r1 [Y] | mov r2 [X] |
| mov [X] 1 | mov [Y] 1 |
当然哪怕reorder不存在,程序的结果仍旧是不确定的(因为这里的内存序不确定),如上所述我们只能说至少有一个人读到1。如果我们希望的是,Larry和Sergey都能读到1呢?
为了解决这样的问题,内存屏障徐徐走出幕后。
为什么单核(Single-core)情况下没有问题
有朋友会问,上面的问题如此的明显,假设它们是一个single-core上的两个process(或thread,在这里原因是一样的),凭什么就没有问题了呢?
首先有了上一篇博客的结果,我们已经知道编译器不会将这些指令重排到有问题的地步了。
到了运行时,对于单核CPU来说(或者按我们上面的理解方式,即程序员Larry),它知道自己在干些什么。如果在单核上要出现上面的问题,首先这个核要在运行时重排process I的代码,且当运行到mov r1 [Y]时,需要被process II中断,然后重排process II的代码,运行mov r2 [X]。
| Process 1 | Process 2 |
|---|---|
| mov r1 [Y] | NOP |
| Interrupted! | mov r2 [X] |
用我们的例子讲,这个程序员Larry需要先开一个branch完了pull些代码之后,abort掉重开一个branch接着pull代码,最后再在两个branch上写东西。
然而很明显我们的处理器并没有这么蠢,它知道自己做了reorder,所以它要么按顺序sequential的跑完,要么跑完process I再中断,要么中断跑完process II再去碰process I。这里所说的任何一种情况下,reorder所带来的问题都会被避免。
内存屏障的类型 & 作用
我们将定义四种内存屏障来解决上面所提到的问题,分别是#LoadLoad / #StoreLoad / #LoadStore / #StoreStore。这四种屏障的名字也就是他们所要解决的问题的名字,举例来说,#StoreStore屏障防止了屏障之前的Store操作被reorder到屏障的Store操作之后。
这四种内存屏障和实际CPU的指令有着紧密的联系,尽管不尽相同————CPU指令常常会是以上的几种屏障的组合。理解了这些内存屏障之后,你就能够理解一系列的CPU指令,以及从一个程序员的角度来说,类似C++11的memory ordering到底是什么样的feature,解决了什么问题。
现在让我们以#StoreLoad为例,理解内存屏障的作用。如下所示,还是上面的例子,同样假设初始状态下a=b=0。
| Processor 1 (Larry) | Processor 2 (Sergey) |
|---|---|
| a.store(1) | b.store(1) |
| r1 = b | r2 = a |
如前所述,我们知道程序结束时,r1=r2=0是可能的发生的。只要两个processor分别reorder自己的两行代码,这样两边的寄存器里就都会存入0。那么现在我们假设加入#StoreLoad屏障。
| Processor 1 (Larry) | Processor 2 (Sergey) |
|---|---|
| a.store(1) | b.store(1) |
| #StoreLoad Fence | #StoreLoad Fence |
| r1 = b | r2 = a |
对于processor I来说,我们只保证了一件事,当它读取b时,a已经完成了store操作(Recall: #StoreLoad防止了屏障之前的store被重排到屏障之后的load后面),对processor II来说是类似的不再赘述。如果没有屏障的保证,我们的四条指令会拥有A(4, 4)种排列组合的可能性(其中就有r1=r2=0的那一种)。然而如果每两条指令都拥有了相对顺序的限制(即a.store(1)一定在r1=b之前且b.store(1)一定在r2=a之前),那么可能的执行情况只有6种,如下所示
| Possibility I | Possibility II | Possibility III | Possibility IV | Possibility V | Possibility VI |
|---|---|---|---|---|---|
| a.store(1) | b.store(1) | a.store(1) | b.store(1) | a.store(1) | b.store(1) |
| b.store(1) | a.store(1) | r1 = b | r2 = a | b.store(1) | a.store(1) |
| r1 = b | r2 = a | b.store(1) | a.store(1) | r2 = a | r1 = b |
| r2 = a | r1 = b | r2 = a | r1 = b | r1 = b | r2 = a |
此时,没有任何一种可能性再会导致r1=r2=0。所以从Larry和Sergey的角度看#StoreLoad,本质上他们此时遵循了一个约定————一旦有本地的改动,我们一定要先push一次然后再pull一次。
写在后面
Jeff的本篇blog是我想翻译的他的blog里我觉得写的相对没有很好的,我个人并不觉得在我理解memory barrier的时候,所谓git的比喻对我起了多大的作用。只能说作为一种简化的方式,它也许能帮助你快速入门,但本质上reorder的问题远没有版本控制那么简单。因此本篇博客我加入了大量自己的想法和参考其他的论文 & 删除了大部分Jeff关于版本控制和memory barrier联系的讲解,本篇博客【下】会从底层和硬件的角度思考reordering,以及memory barrier真正的作用。