双重检查锁定模式(Double-Checked Locking Pattern)的陷阱
This article is partly referred to & translated from Jeff Preshing’s blog, which helps me a lot with understanding the low-level insight of C++ concurrency. I’ll try to convey my understanding of the blog correctly to my best knowledge with my own experiment results & comments.
单例我们用的很多了,所谓“懒汉式”单例也是设计模式中非常常见的一个例子。很多博客、技术帖子都会告诉你,简单的懒汉式单例在多线程的context下,仍旧是不安全的。这篇博客想仔细地告诉你为什么它仍旧不安全,以及解决方案。
什么是双重检查锁定模式(DCLP)
假设你需要实现一个线程安全的单例类(Singleton)的设计模式,最简单直接的方法当然是直接加锁。这种情况下,两个线程(thread)同时调用Singleton::getInstance()时,只有其中一个会创建实例。
1 | class Singleton { |
当然很明显这样的程序有着很大的缺陷。虽然锁本身并不会带来很大的overhead,但是锁竞争(Lock Contention)会。在上面的代码里,如果有很多的线程同时需要调用单例类(也是一个常见的use case),整个程序会变得很慢。如果线程数目scale up,程序的contention将会非常严重。
在这个设计模式中,一种经常被提起的设计方式就是DCLP。尽管现如今很多人都会选择用local static或call once的方式实现,DCLP仍旧是经典的模式之一。早年间我写单例类的codes基本都是下面这样,也是DCLP最常见的形式
1 | class Singleton { |
那么问题来了,以上这段经常出现在单例教学的C++代码究竟有什么陷阱呢?
Break down to Low Level
我们都知道为了加速程序,编译器(compiler)和处理器(Processor)会分别在编译时和运行时对指令进行重排(reorder)。由于大多数情况下,一行C++代码很可能并不是原子性的,在重排 / 多线程的语境下,会发生非常多的问题。这里请大家把目光放到创建Singleton的这行代码
1 | m_instance = new Singleton(); |
初始化一个类会让汇编变得复杂,考虑(*)行的代码,初始化一个整数指针,在我的电脑上用gcc编译成汇编(gcc -S)会看到以下的codes
1 | call operator new(unsigned long) |
简单来讲就是这一行code一共需要三步完成
- 申请一块内存(operator new)
- 初始化内存地址(initialization)
- 将指针指向初始化后的内存地址
乍一看毫无问题,然而我们假设处理器进行了reorder,执行顺序变成了1 -> 3 -> 2呢?如果此时线程I执行到了创建Singleton这一步,由于指令重排先执行完成了1和3,在2还没有执行的时候,另一个线程II恰好执行到了第一次check nullptr,危险的事情就发生了!此时线程II将直接返回一个未初始化的内存地址,使用它的程序将会产生无法预知的结果。
1 | class Singleton { |
更详细的DCLP内容可以参考Meyers-Alexandrescu的论文。
什么才是正确的DCLP – C++11的Acquire & Release Fence
C++11的重要之处,就是它填补了此前多线程中无可空缺的一部分语义,在C++11之前,没有任何办法能够合理地实现DCLP这一功能(当然指的是C++语法本身里没有啦、大佬总是会有办法的)。而到了C++11,atomic能帮你解决这一切。正确的做法如下
1 | std::atomic<Singleton*> Singleton::m_instance; |
现在这个codes即便是在多核系统(multi-core system)下都能非常好地运行,因为memory fence的同步(sychronize with)语义保证了所有的改动都能被需要的线程所看到(下图引自Jeff Preshing’s blog)。
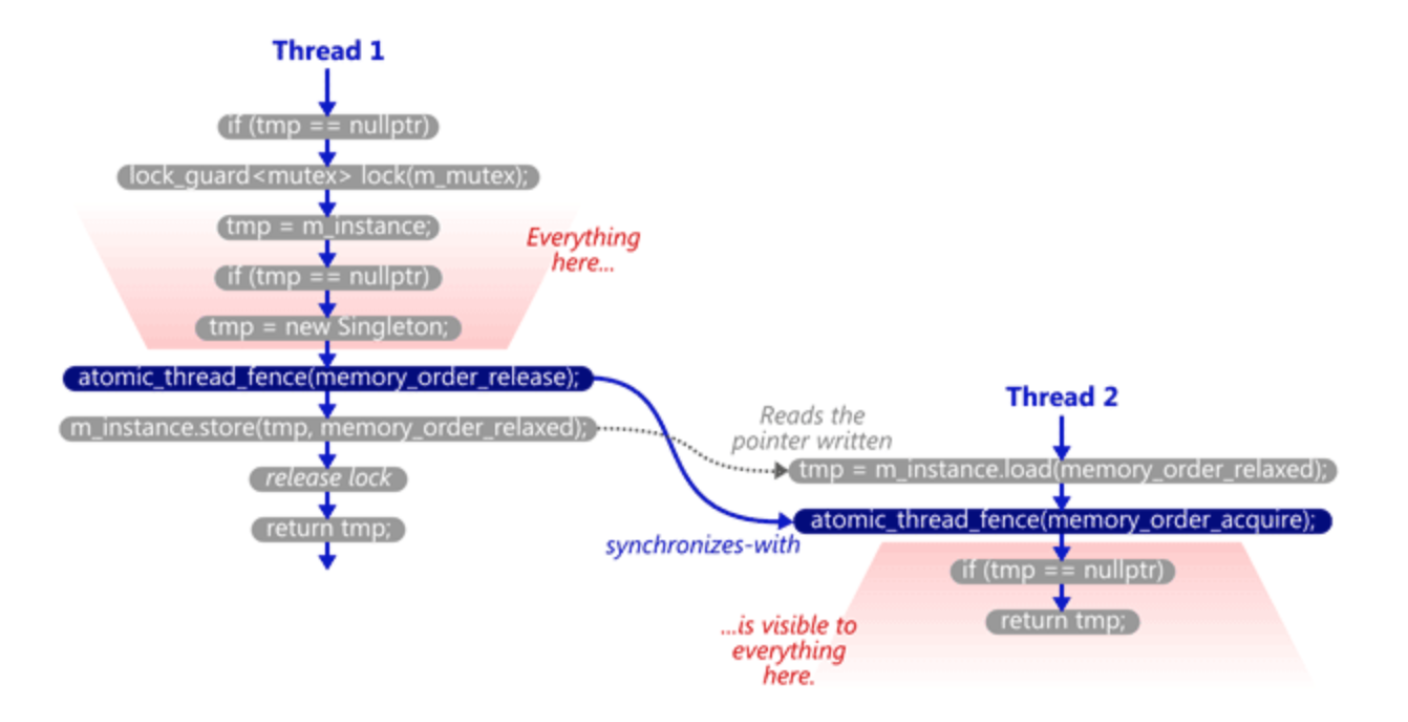
这也是所有错误的DCLP实现所缺的那一环 ———— 同步语义。如果没有memory fence存在,我们根本没办法保证第一个线程所做的修改在第二个线程中是可见的。
所以我为什么要用DCLP
是的,单例类已经好多年没人用DCLP去实现了。一个最常见的static local实现就能解决所有的问题,为什么我要研究这些乱七八糟的呢
1 | Singleton& Singleton::getInstance() { |
Well那我想问,static本质上如何保证了这个单例类的线程安全呢?答案是(至少在我的gcc上)DCLP!当然更重要的是,DCLP也不仅仅可以用于单例,线程安全的map之类的数据结构,也可以用到DCLP的实现。当然近来还有很多人喜欢用call_once来实现单例
1 | Singleton* Singleton::instance= nullptr; |
关于call_once我并没有太多的了解。。但是根据线程安全Singleton速度实验来看,大概率并不是什么efficient的实现方式。所以在没有问题的情况下,想写一个线程安全Singleton最好的方式大概还是local static吧。
写在后面
这篇blog本身Jeff还囊括了更多内容,有的我并没有验证、有的以我现在的水平也不能完全理解所以我也并没有翻译。大多数内容还是我自己的实验 & 想法。这个系列(C++ Low-level Concurrency)应该还会继续不短的时间,一方面是翻译Jeff的blog里我认为非常好的部分、另一方面是写一些读《C++ Concurrency in Action》的想法和实验。大概就是这样啦,这篇blog也是最初引发我想开这整个博客的原因,希望能对机缘巧合点进来的人有所帮助啦。